728x90
반응형
오늘은 데이터 분석의 기본 EDA(Exploratory Data Analysis, 탐색적 데이터 분석) 에 대해 스터디한 내용을 정리해보려고 해요.
단순히 그래프 몇 개 그리는 게 아니라, 데이터의 상태를 꼼꼼히 점검하고, 인사이트를 얻는 과정이라는 걸 다시 한 번 느꼈습니다.
1. Basic Analysis 코드 정리
데이터를 받으면 가장 먼저 실행하는 기본 코드들! 아래 코드들은 판다스 DataFrame을 기준으로 설명합니다.
df_train.head() # 상위 5개 행 출력
df_train.tail() # 하위 5개 행 출력
df_train.shape # (행 개수, 열 개수) 출력
df_train.info() # 각 열의 데이터 타입과 결측치 개수 확인
df_train.describe() # 수치형 열의 기초 통계량 (평균, 표준편차 등)
df_train[col].nunique() # 특정 열의 고유값 개수 확인
df_train[col].value_counts() # 특정 열의 각 값 별 빈도 확인
2. EDA(탐색적 데이터 분석)란?
EDA는 데이터를 깊게 이해하기 위한 첫 단계예요. 그래프를 예쁘게 그리는 게 목적이 아니라, 데이터의 품질을 점검하고, 인사이트(숨겨진 정보나 패턴)를 찾는 것이 진짜 목적입니다.
1) 데이터 품질 점검하기
- 결측치(Null, NaN) 비율 및 패턴 확인:
결측치가 얼마나 있고, 어디에 집중되어 있는지 확인해야 해요.
보통 결측치가 적으면 행을 삭제할 수 있지만, 많거나 중요한 정보라면
평균값, 중앙값 등으로 대체하거나, 도메인 지식으로 채우는 방법도 있습니다. - 이상치(Outlier) 탐지:
눈에 띄게 튀는 값이 있는지, 잘못된 데이터는 아닌지 점검합니다.
삭제하거나, 적절히 수정하는 등의 처리가 필요해요.
2) 인사이트 발견하기
- Feature Engineering 기회 발굴:
데이터 조합, 파생 변수 생성 등 더 좋은 모델을 만들 수 있는 아이디어를 찾는 시간! - 모델 선택의 근거 만들기:
예를 들어, 변수와 타겟 간의 관계를 보며 로지스틱 회귀 같은 모델을 선택할 수 있습니다. - 의미 해석 및 결과 도출:
데이터 분석 결과를 어떻게 해석할지, 실제로 어떤 시사점이 있는지 생각해봅니다.
추가적으로 점검할 것들
- 데이터의 왜도(분포의 비대칭성), 스케일 차이(변수 단위), 상관관계, 다중공선성 등
→ 필요하다면 로그 변환, 스케일링, 변수 삭제, PCA 등도 고려합니다.
3. 결측치 & 이상치 관리
결측치(Missing Value) 처리
- 행 삭제: 결측치가 소수일 때만 추천.
데이터 손실이 심할 수 있음에 유의! - 대체(평균, 중앙값 등): 데이터의 분포에 따라 대체 방법 선택.
- 도메인 지식 활용: 해당 분야 전문가 의견도 중요.
이상치(Outlier) 탐지와 처리
- 도메인 지식 기반 처리: 단순히 값이 튀었다고 무조건 삭제하는 게 아니라,
현업에서 실제로 불가능한 값인지 고려해서 결정해야 합니다.
4. 실제 사례 소개
인구 구조 변화와 어린이 공원 입지 특성 분석 연구
예시로, ‘어린이 공원 면적 비율’과 ‘유소년 인구 비율’을 비교하는 LQ(Location Quotient) 지수를 구할 수 있습니다.
- LQ = (AI / A) / (PI / P)
- AI: 자치구 I의 어린이 공원 면적
- A: 전체 어린이 공원 면적
- PI: 자치구 I의 유소년 인구
- P: 전체 유소년 인구
실제 데이터 전처리 예시로는 만 0세, 만 4세, 만 5~9세를 묶어서 ‘유소년 인구수’로 정의한 것도 소개됐어요.
5. 연속형 변수 시각화 - 주요 그래프 소개
연속형 변수(수치형 데이터)를 시각화할 때 많이 쓰는 그래프들입니다.
- 히스토그램: 데이터 분포 파악
- 상자 그림(Boxplot): 이상치, 분포 확인
- 밀도 그래프: 분포의 부드러운 곡선 형태
- 산점도(Scatter Plot): 두 변수의 관계 시각화
- 페어플롯: 여러 변수 조합별 산점도와 히스토그램을 한 번에
- 상관관계 히트맵: 변수 간 상관관계 한눈에 보기
- 선 그래프: 시간 흐름에 따른 값 변화
6. 다음 시간 과제 중 일부 기록
📊 상관관계 히트맵(Correlation Heatmap)으로 데이터 전체 흐름 파악하기
데이터셋에 다양한 수치형 기상 데이터가 있을 때, 각 변수들(기온, 기압, 습도, 구름 등)이 서로 어떻게 연결되어 있는지
한눈에 보기 좋은 차트가 바로 상관관계 히트맵입니다.
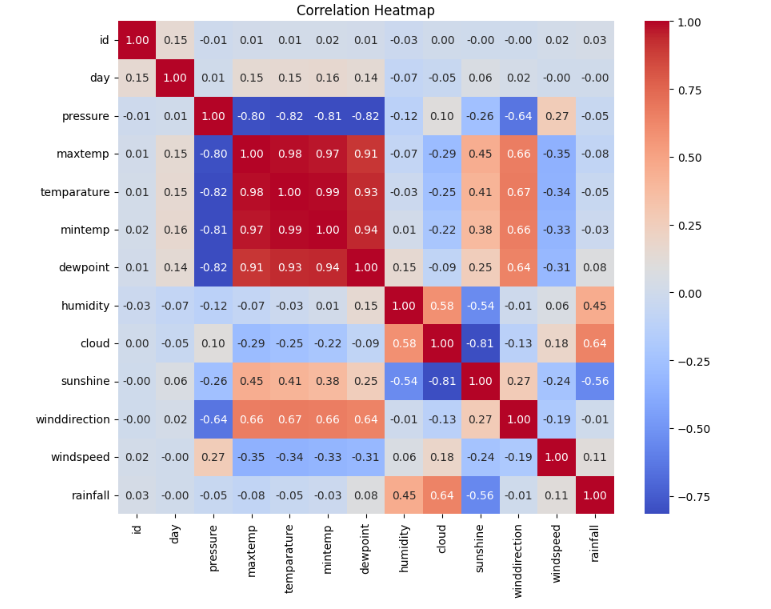
이 차트는
- 어떤 변수끼리 강하게(혹은 약하게) 연관되어 있는지 rainfall(강수/비)와 다른 변수와의 관계가 뭔지
를 색깔로 쉽게 보여줍니다.
📝 코드 예시
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10, 8))
sns.heatmap(train.corr(), annot=True, cmap='coolwarm', fmt=".2f")
plt.title('Correlation Heatmap')
plt.show()
코드 설명
- train.corr() : 데이터프레임의 수치형 변수들끼리 상관계수를 계산합니다.
- sns.heatmap(..., annot=True, cmap='coolwarm') : 상관계수 행렬을 색깔로 시각화하고, 숫자도 같이 보여줍니다.
- fmt=".2f" : 소수점 둘째자리까지 표시해서 보기 쉽게!
- plt.figure(figsize=(10, 8)) : 차트 크기를 넉넉하게 키워줍니다.
📈 차트 해석법
- 진한 파란색: 두 변수는 서로 비슷하게(같이 오르내리며) 변합니다. (양의 상관관계)
- 진한 빨간색: 한쪽이 오를 때 다른 쪽은 내려가는 경향이 큽니다. (음의 상관관계)
- 하얀색~연한색: 서로 특별한 연관성 없음
예를 들어, rainfall과 습도, 구름, 기압 등 주요 변수와의 관계가 어떠한지 숫자와 색깔로 바로 알 수 있습니다.
728x90
반응형
'직장인 대학원 > 캐글 스터디' 카테고리의 다른 글
| 캐글 스터디 1회차 - 과제 (0) | 2025.04.14 |
|---|---|
| 캐글 스터디 1회차 - 캐글이란 .. (0) | 2025.04.07 |

댓글