기존에 데이터 다중 삽입 할 때의 방식
public void insertMultipleV2vFailWord(List<V2vFailWord> entities) {
for (V2vFailWord entity : entities) {
jm.em.persist(entity);
}
}
아래와 같이 insert 쿼리문이 반복적으로 발생하기 때문에 성능 저하가 발생할 수 밖에 없다.
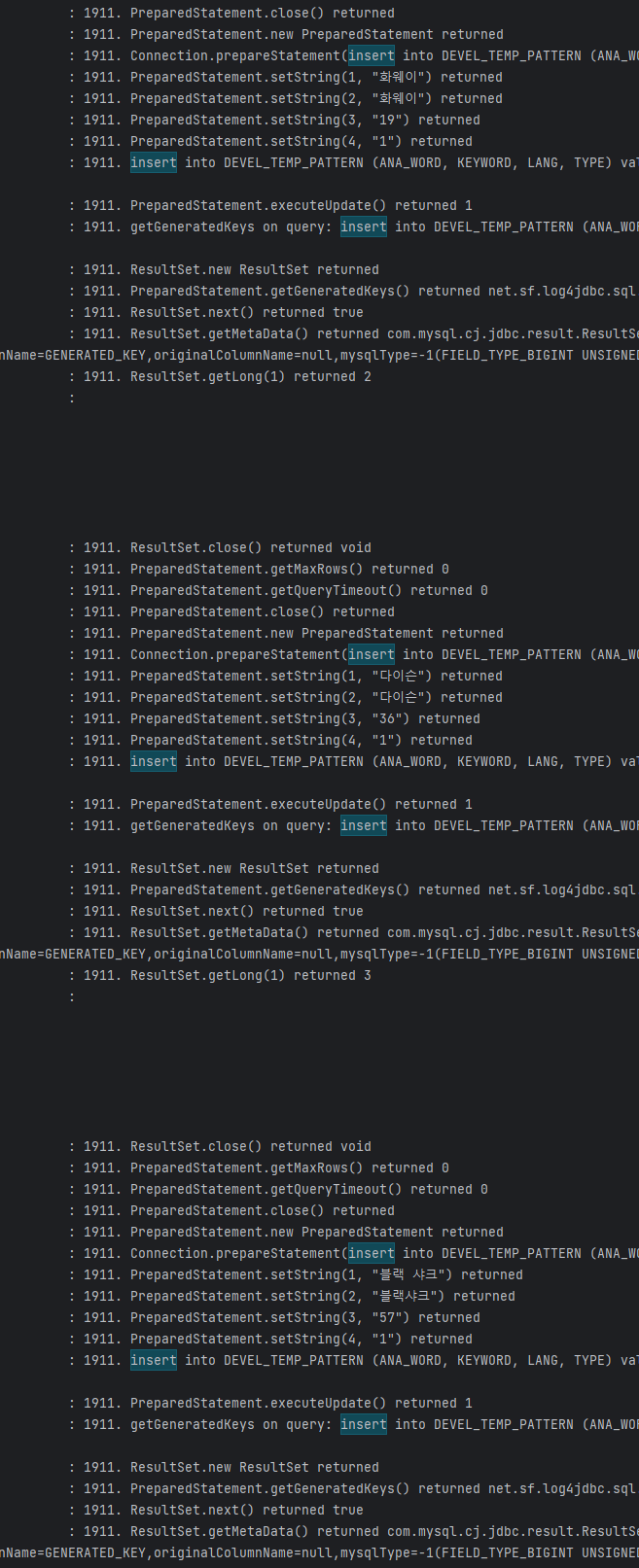
JPA 는 Bulk Insert 가 안될까 ?
여기 참조하니까 아래와 같이 답변이 나와있다.
Transactional write-behind
Hibernate tries to defer the Persistence Context flushing up until the last possible moment. This strategy has been traditionally known as transactional write-behind.
The write-behind is more related to Hibernate flushing rather than any logical or physical transaction. During a transaction, the flush may occur multiple times.
The flushed changes are visible only for the current database transaction. Until the current transaction is committed, no change is visible by other concurrent transactions.
IDENTITY
The IDENTITY generator allows an int or bigint column to be auto-incremented on demand. The increment process happens outside of the current running transaction, so a roll-back may end up discarding already assigned values (value gaps may happen).
The increment process is very efficient since it uses a database internal lightweight locking mechanism as opposed to the more heavyweight transactional course-grain locks.
The only drawback is that we can’t know the newly assigned value prior to executing the INSERT statement. This restriction is hindering the transactional write-behind flushing strategy adopted by Hibernate. For this reason, Hibernates disables the JDBC batch support for entities using the IDENTITY generator.
TABLE
The only solution would be to use a TABLE identifier generator, backed by a pooled-lo optimizer. This generator works with MySQL too, so it overcomes the lack of database SEQUENCE support.
However, the TABLE generator performs worse than IDENTITY, so in the end, this is not a viable alternative.
Conclusion
Therefore, using IDENTITY is still the best choice on MySQL, and if you need batching for insert, you can use JDBC for that.
한국말로 번역해보면
Hibernate는 Persistence Context의 flushing을 최대한 미룰려고 노력합니다. 이 전략은 전통적으로 트랜잭셔널 write-behind라고 알려져 있습니다.
write-behind는 논리적 또는 물리적 트랜잭션보다는 Hibernate flushing과 더 관련이 있습니다. 트랜잭션 동안에는 여러 번 flush가 발생할 수 있습니다.
flush된 변경사항은 현재 데이터베이스 트랜잭션에만 표시됩니다. 현재 트랜잭션이 커밋되기 전까지 다른 동시 트랜잭션에서는 변경 사항이 보이지 않습니다.
IDENTITY
IDENTITY 생성기는 int 또는 bigint 열을 요청시 자동 증가시킬 수 있게 합니다. 증가 과정은 현재 실행 중인 트랜잭션 외부에서 발생하므로 롤백이 이미 할당된 값을 폐기할 수 있습니다 (값 간격이 발생할 수 있습니다).
증가 과정은 데이터베이스 내부의 경량 잠금 메커니즘을 사용하기 때문에 매우 효율적입니다. 이는 더 무거운 트랜잭셔널 잠금에 비해 경량입니다.
유일한 단점은 INSERT 문을 실행하기 전에 새로 할당된 값을 알 수 없다는 것입니다. 이 제한은 Hibernate가 채택한 트랜잭셔널 write-behind flushing 전략을 방해합니다. 이러한 이유로, Hibernate는 IDENTITY 생성기를 사용하는 엔터티에 대한 JDBC 배치 지원을 비활성화합니다.
TABLE
유일한 해결책은 풀드-lo optimizer를 지원하는 TABLE 식별자 생성기를 사용하는 것입니다. 이 생성기는 MySQL에서도 작동하므로 데이터베이스 SEQUENCE 지원의 부족을 극복합니다.
그러나, TABLE 생성기는 IDENTITY보다 성능이 떨어집니다. 따라서 결국, 이것은 실용적인 대안이 아닙니다.
결론
따라서, MySQL에서는 여전히 IDENTITY를 사용하는 것이 최선의 선택이며, insert를 위해 배치가 필요한 경우 JDBC를 사용할 수 있습니다.
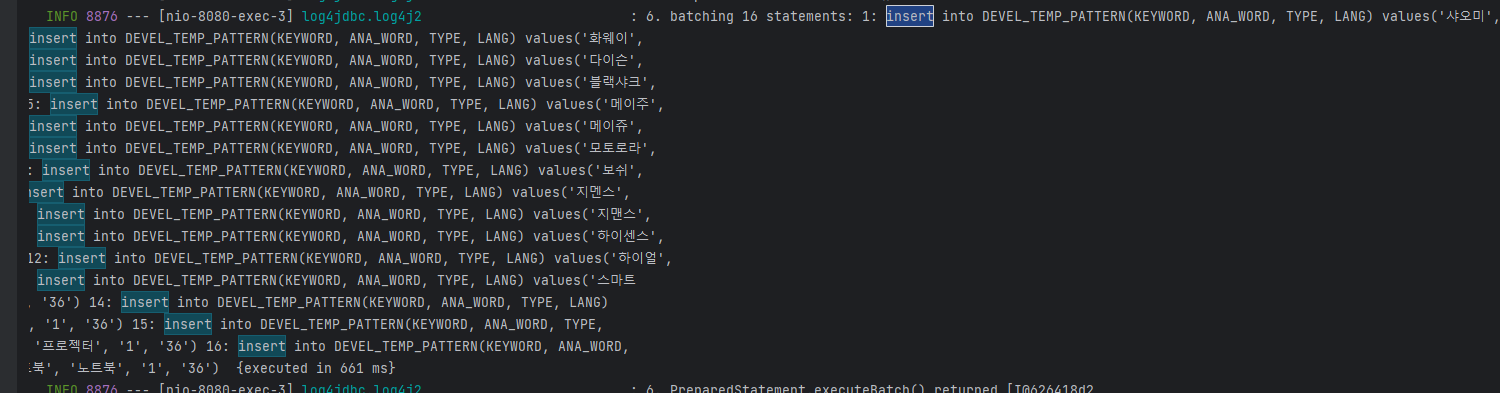
그래서 아래와 같이 JdbcTemplate 를 선언해서 사용했다.
@Repository
@RequiredArgsConstructor
public class V2vJdbcRepository {
@V2vJdbcManager
private final JdbcTemplate jdbcTemplate;
public void insertBulkV2vFailWord(List<V2vFailWord> entities) {
jdbcTemplate.batchUpdate("insert into DEVEL_temp_word(KEYWORD, LANG) " +
"values(?, ?)",
new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setString(1, entities.get(i).getKeyword());
ps.setString(2, entities.get(i).getLang().getType());
}
@Override
public int getBatchSize() {
return entities.size();
}
});
}
}

'개발중 > Java Persistence API (JPA)' 카테고리의 다른 글
| [JPA] 낙관적 락(Optimistic Lock)과 비관적락 (Pessimistic Lock) 이란 ? (1) | 2024.01.17 |
|---|---|
| [JPA] Entity 가 Update 되는 과정에 대해서 아니 (0) | 2023.06.27 |
| [JPA ERROR] No qualifying bean of type 'org.springframework.transaction.TransactionManager' available (0) | 2023.03.15 |
| [JPA] 다른 컬럼명을 참조하는 연관관계에 대한 궁굼점 (referencedColumnName) (0) | 2023.02.13 |
| Criteria API 에 대해 알아보기 (0) | 2023.01.27 |

